
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
A Paradigm for Data-Free Reinforced Self-Play Reasoning in LLMs


The authors introduce Absolute Zero, a novel Reinforcement Learning with Verifiable Rewards (RLVR) paradigm where an LLM learns and enhances its reasoning abilities without any reliance on external, human-produced data. This stands in contrast to existing RLVR approaches that, while avoiding supervised labeling of the reasoning process, still depend on curated collections of questions and answers. The paper posits that the scarcity of high-quality human examples poses scalability challenges and may limit learning potential, especially for future superintelligent systems.
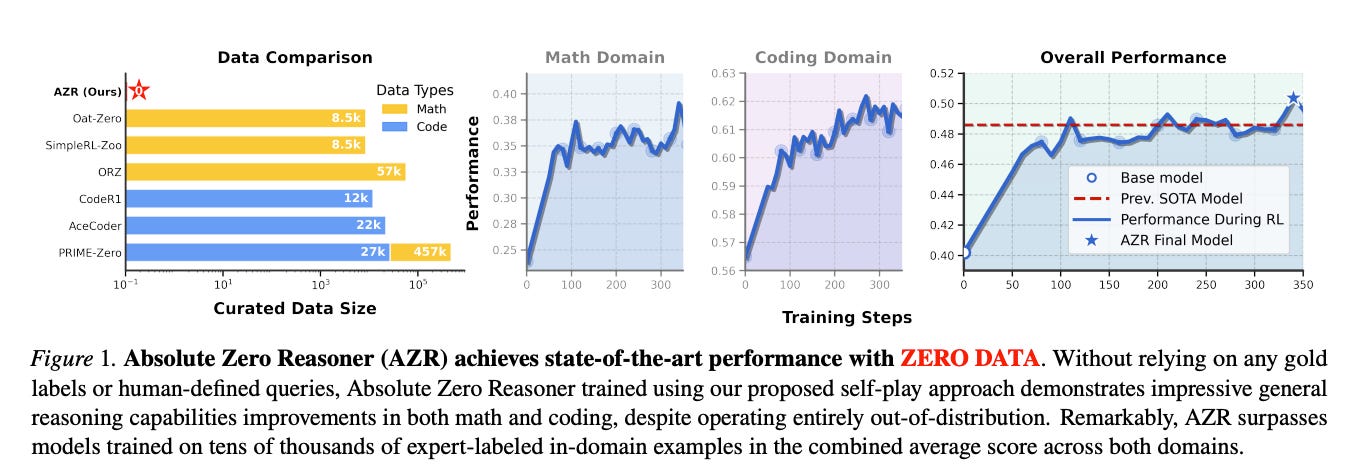
The proposed Absolute Zero Reasoner (AZR) embodies this paradigm. AZR features a single model that learns to propose tasks maximizing its own learning progress and improves its reasoning by solving these self-generated tasks. A code executor serves as a unified environment to both validate the proposed code reasoning tasks and verify the model's answers, providing a verifiable reward signal for open-ended yet grounded learning. Remarkably, despite being trained entirely without external data, AZR is reported to achieve overall state-of-the-art (SOTA) performance on coding and mathematical reasoning benchmarks, surpassing existing "zero-setting" models that utilize tens of thousands of in-domain human-curated examples. The authors also demonstrate AZR's effective applicability across different model scales and its compatibility with various model classes.
1. Introduction: The Imperative for Data-Independent Reasoning
The paper commences by contextualizing the role of Reinforcement Learning with Verifiable Rewards (RLVR) in augmenting the reasoning skills of LLMs. It critically identifies the dependencies of current RLVR methods on manually curated datasets, highlighting inherent limitations concerning long-term scalability and the potential constraints imposed by human-defined tasks, particularly in scenarios where AI might exceed human cognitive capacities.
To surmount these challenges, the "Absolute Zero" paradigm is proposed. This approach empowers a single model to autonomously generate its learning curriculum by proposing tasks tailored to its current learning frontier, and subsequently enhance its reasoning capabilities by solving these self-proposed challenges. The introduction of the Absolute Zero Reasoner (AZR) system sets the stage, a system designed to self-evolve its training curriculum and reasoning prowess using a code executor for task validation and solution verification. The authors foreshadow AZR's significant empirical results and allude to several key findings, including the amplification of reasoning through code priors and notable cross-domain knowledge transfer.
2. The Absolute Zero Paradigm: Principles of Self-Generated Learning
This section formally articulates the Absolute Zero paradigm, drawing distinctions from Supervised Fine-Tuning (SFT) and conventional RLVR.
2.1. Preliminaries: The paper notes that SFT necessitates comprehensive datasets comprising task-rationale-answer demonstrations. RLVR, while obviating the need for labeled rationales by leveraging outcome-based feedback, still typically relies on expert-defined distributions of learning tasks and answers. Both approaches are thus tethered to human-curated data, limiting their ultimate scalability.
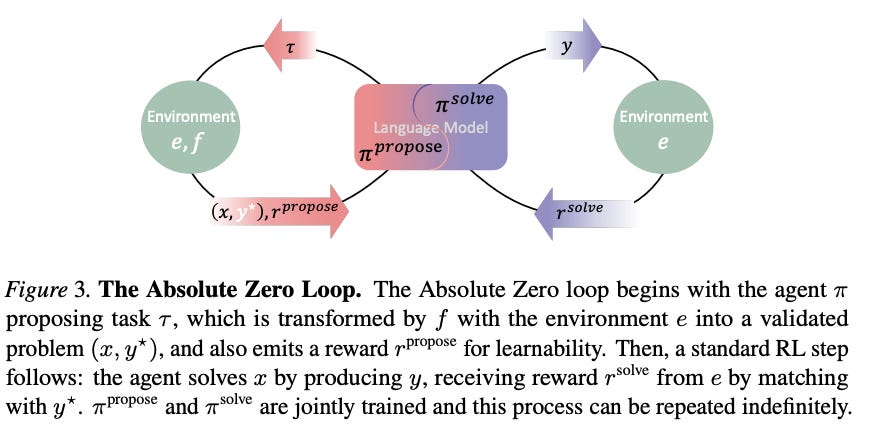
2.2. Absolute Zero: The core tenet of Absolute Zero is the elimination of this external data dependency. The paradigm facilitates a self-play mechanism wherein the model itself assumes the dual roles of task proposer and task solver. The proposer samples a task, which is then validated by an external environment (e.g., a code executor), thereby creating a verifiable reasoning task. The solver component of the model then generates a solution. Through this continuous cycle of proposal, validation, solution, and verification, the proposer and solver are jointly trained, enabling indefinite and autonomous learning.
3. The Absolute Zero Reasoner (AZR) System: Architecture and Operation
The Absolute Zero Reasoner (AZR) is the practical instantiation of the Absolute Zero paradigm. Its architecture revolves around a single language model that dynamically performs two primary roles:
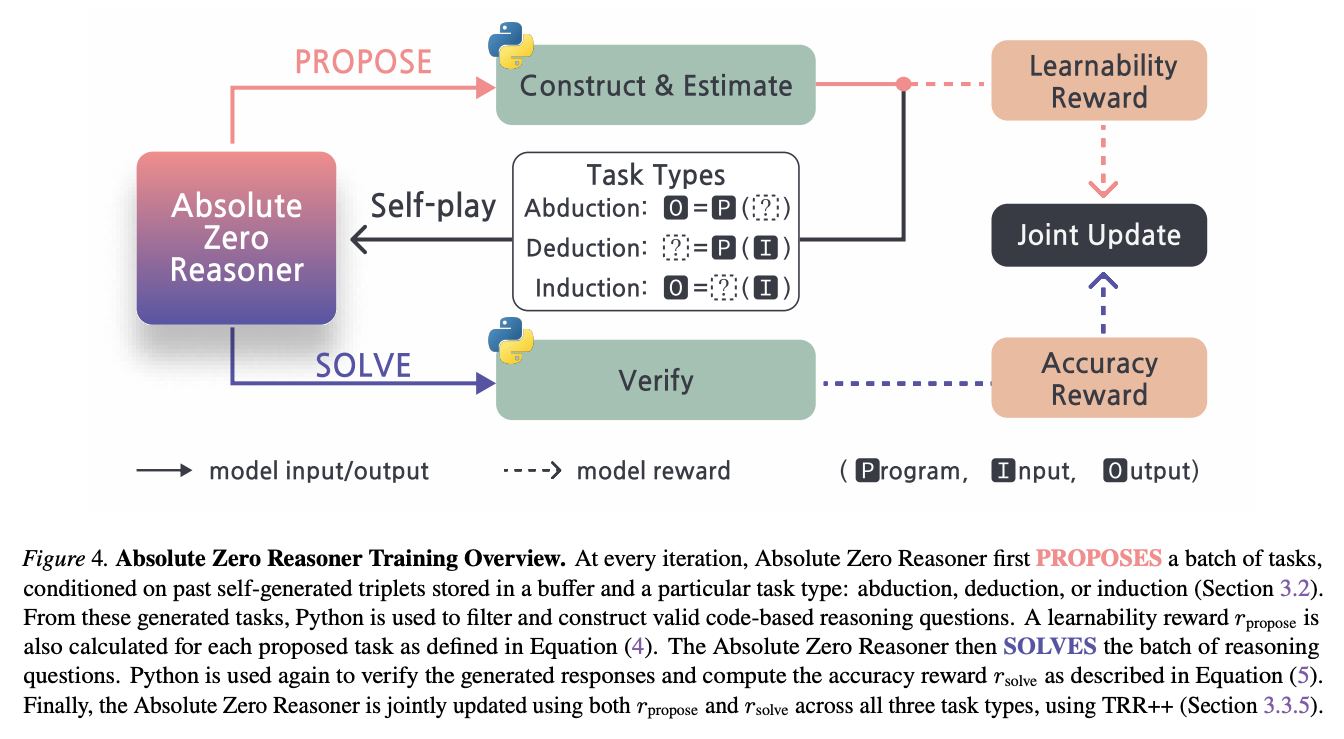
Proposer: This role involves generating novel tasks. Specifically, AZR is designed to construct three types of coding tasks, corresponding to three complementary modes of reasoning:
Induction: Inferring general rules or patterns from specific examples.
Abduction: Deducing the most plausible explanation for an observation.
Deduction: Applying general rules to specific instances to arrive at a conclusion. These tasks are typically framed around program, input, and output triplets, where one element is to be inferred or reasoned about.
Solver: This role attempts to solve the tasks proposed by the proposer (and validated by the environment). A crucial component of the AZR system is the code executor, which serves as the objective environment. The executor validates the syntactical and logical soundness of tasks generated by the proposer and, critically, verifies the correctness of solutions generated by the solver. This provides the verifiable reward signal necessary for reinforcement learning. The entire AZR system is trained end-to-end using a reinforcement learning advantage estimator specifically tailored to the multitask nature of this self-play approach.
4. Self-Evolution and Learning Mechanism in AZR
AZR's capacity for self-improvement stems from an iterative self-learning (or self-evolution) loop:
Task Proposal: The model, in its proposer role, generates a potential reasoning task.
Task Validation: The code executor (environment) validates this task. If valid, it becomes part of the dynamic training curriculum.
Task Solving: The model, in its solver role, attempts to solve the validated task.
Solution Verification & Reward: The code executor verifies the correctness of the solution. Based on this outcome (success or failure), a reward signal is generated.
Model Update: This reward is used to update the parameters of the single underlying language model using reinforcement learning algorithms. This update refines the model's abilities in both proposing appropriately challenging and solvable tasks and in effectively solving them. This cycle repeats continuously, enabling AZR to progressively enhance its reasoning capabilities and adapt its internal training curriculum without recourse to any external datasets or human intervention.
5. Experimental Validation and Performance of AZR
Despite its data-free training methodology, AZR's performance was rigorously evaluated against standard benchmarks.
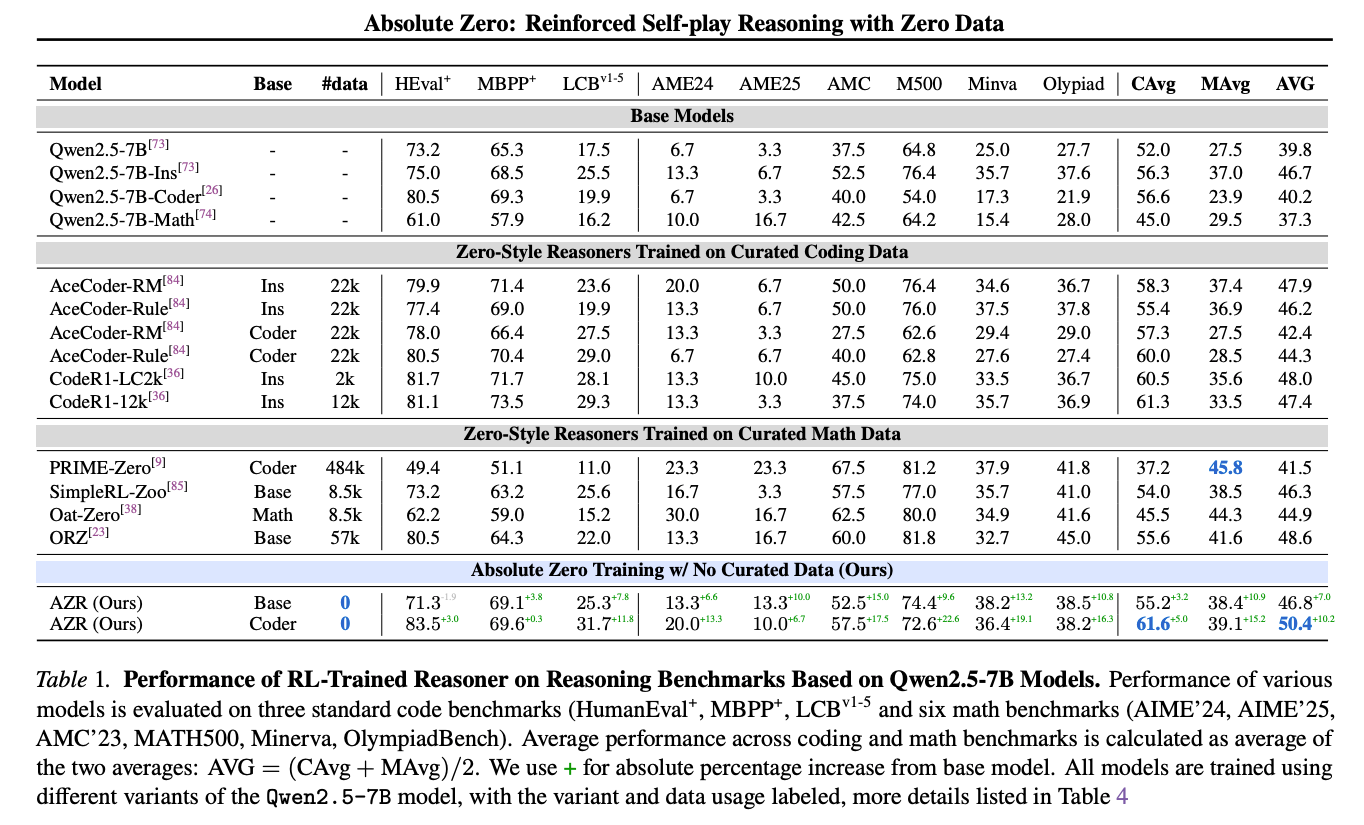
Experimental Setup: AZR was implemented using base models such as Qwen2.5-7B and trained entirely through its self-play mechanism without any external training data.
Evaluation Benchmarks: Its reasoning abilities were tested on a suite of established coding benchmarks (including HumanEval+, MBPP+, LCBv1-5) and mathematical reasoning benchmarks (such as AIME'24, AIME'25, AMC'23, MATH500, Minerva, and OlympiadBench).
Key Performance Results: The paper reports that AZR achieves state-of-the-art (SOTA) performance across both coding and mathematical reasoning tasks. Notably, it outperforms existing "zero-setting" models that, while not using supervised reasoning traces, still rely on tens of thousands of human-curated problem-answer pairs for their training. Furthermore, AZR demonstrates strong cross-domain transfer of reasoning skills and shows that its performance improvements scale effectively with increasing model size.
6. Implications of Data-Free Reasoning
The paper concludes by discussing several emergent properties and broader implications of the Absolute Zero paradigm and the AZR system:
Amplification of Reasoning by Code Priors: The use of a code execution environment appears to effectively ground and amplify the model's reasoning development.
Pronounced Cross-Domain Transfer: AZR exhibits significant ability to transfer reasoning skills learned in one domain (e.g., coding) to others (e.g., mathematics).
Scalability with Model Size: Performance improvements are shown to scale with the size of the base language model used for AZR.
Emergent Behaviors: The system demonstrates emergent behaviors, such as the generation of comments that function as intermediate plans within its problem-solving processes.
Cognitive Behavior Variation: The study observes that cognitive behaviors and token length in generated solutions vary depending on the reasoning mode (induction, abduction, deduction) being employed.
Safety Considerations: The authors also note the observation of "occasional concerning chains of thought" produced by AZR, highlighting an area for future investigation regarding the safety and alignment of such self-evolving systems.
Final Remarks
"Absolute Zero: Reinforced Self-play Reasoning with Zero Data" presents a paradigm shift in training LLMs for reasoning tasks. By demonstrating that a model can bootstrap and significantly enhance its reasoning capabilities entirely through self-generated tasks and verifiable feedback from a programmatic environment, this work opens new avenues for developing highly capable AI systems with reduced reliance on human-curated data. The reported SOTA performance of AZR, coupled with its novel training methodology, marks a significant step towards more autonomous and scalable AI reasoning. The discussion on emergent behaviors and safety also underscores important considerations for future research in this domain.